巨量資料的三種處理工具
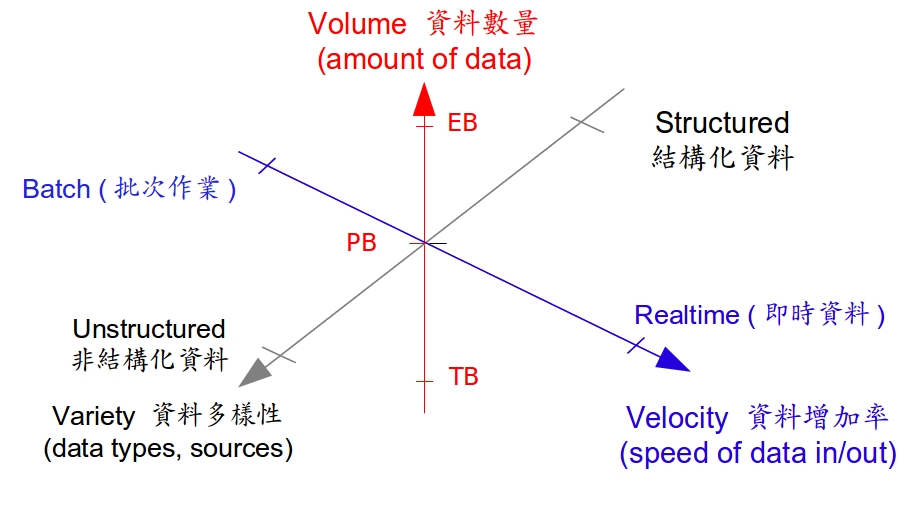
Source : “High Throughput Computing Technologies”, by Jazz Yao-Tsung Wang, September 12, 2013
BIG DATA AT REST
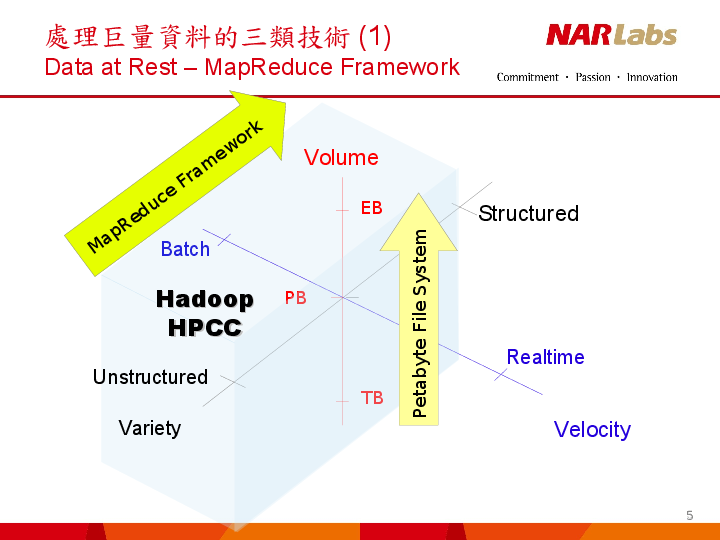
Source : “High Throughput Computing Technologies”, by Jazz Yao-Tsung Wang, September 12, 2013
BIG DATA IN MOTION
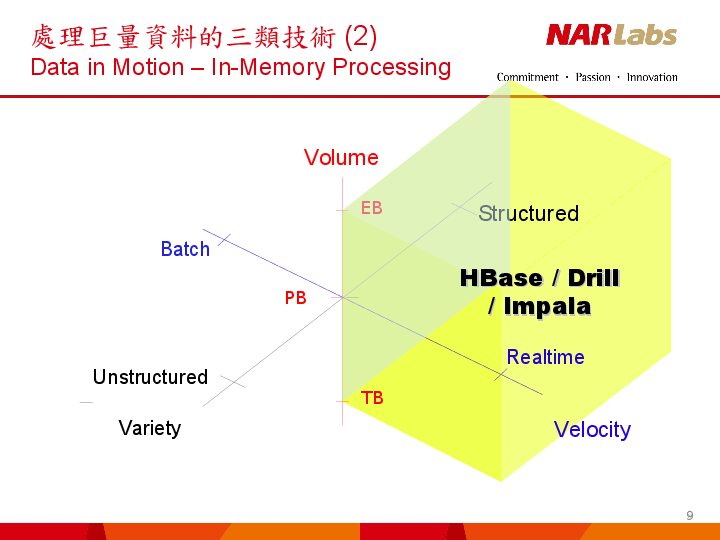
Source : “High Throughput Computing Technologies”, by Jazz Yao-Tsung Wang, September 12, 2013
BIG DATA IN MOTION
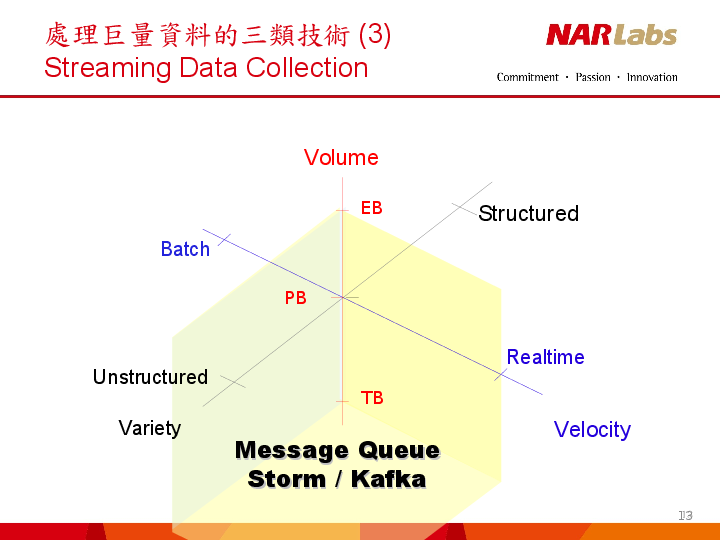
Source : “High Throughput Computing Technologies”, by Jazz Yao-Tsung Wang, September 12, 2013
Apache Big Data Stack (1)
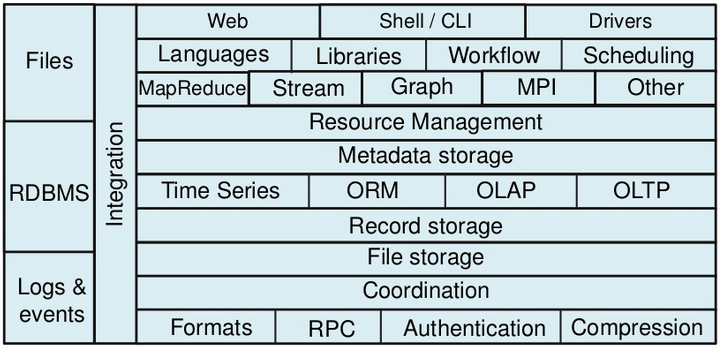
Source : “The Hadoop Stack - Then, Now and in the Future”, Hadoop World 2011
Apache Big Data Stack (2)
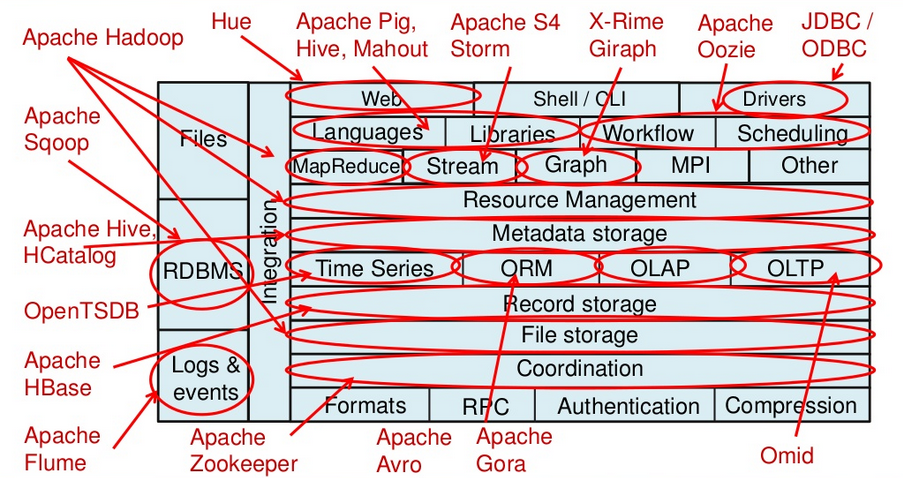
Source : “The Hadoop Stack - Then, Now and in the Future”, Hadoop World 2011
Sqoop Import (匯入)
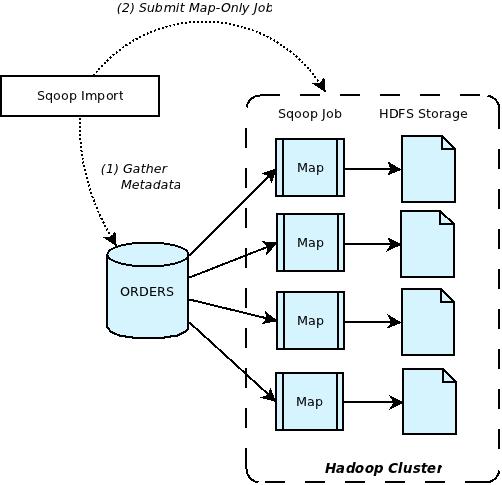
Source : “Apache Sqoop – Overview”, by Arvind Prabhakar, October 06, 2011
Sqoop Export (匯出)
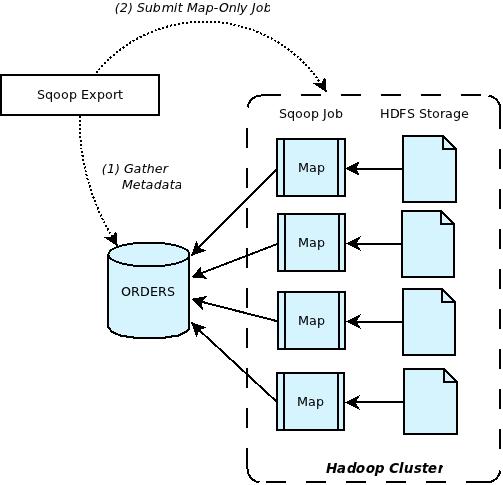
Source : “Apache Sqoop – Overview”, by Arvind Prabhakar, October 06, 2011